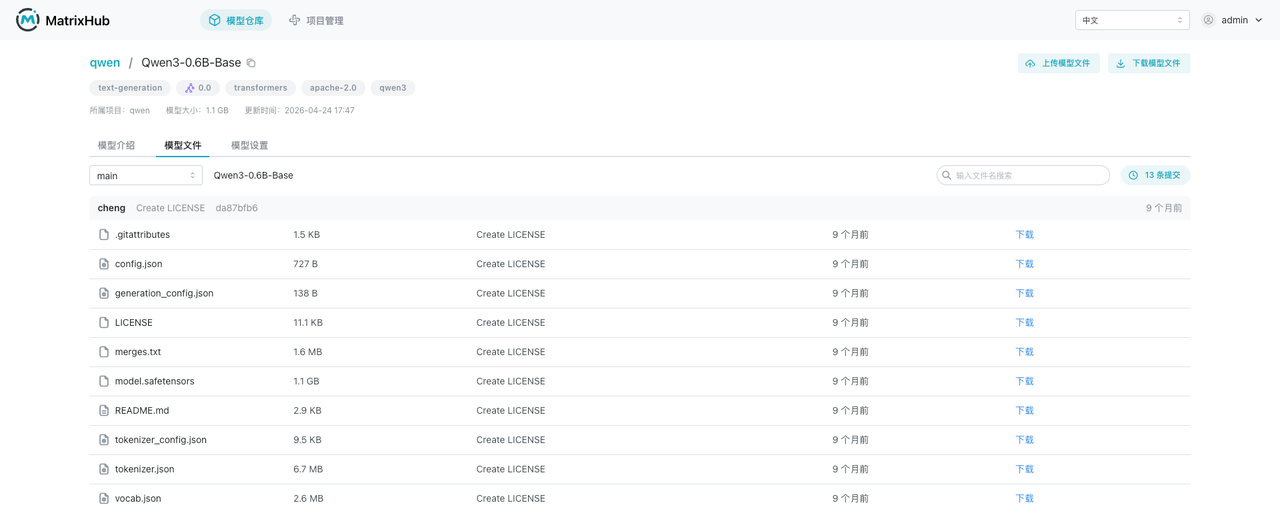
示例
· 阅读需 2 分钟
这里放一个 MatrixHub 的真实使用示例。
常用场景
内网 vLLM 集群的大规模分发
- 场景描述:内网生产环境部署了一个由 100 台 GPU 服务器组成的 vLLM 推理集群。由于模型文件很大,例如 70B 模型可能超过 130GB,如果每台机器都去公网 Hugging Face 拉取,不仅耗时很长,还可能触发公网带宽限流。
- 流程概览:
- 统一接入点:将所有 vLLM 节点的
HF_ENDPOINT环境变量统一指向内网 MatrixHub 地址。 - 拉取即缓存:首台机器请求模型时,MatrixHub 自动从公网拉取并持久化到本地;后续节点请求将直接命中内网缓存。
- 统一接入点:将所有 vLLM 节点的
作为用户,我希望把
hf download的 Endpoint 指向 MatrixHub,这样当同一内网里的其他节点再次拉取同一模型时,可以直接享受缓存带来的速度提升。
操作步骤
- 访问 MatrixHub 地址
http://x.x.x.x:3001,进入登录页面。

- 使用 admin 用户登录平台,进入模型仓库列表。

- 点击右上角用户菜单,进入平台设置和仓库管理。
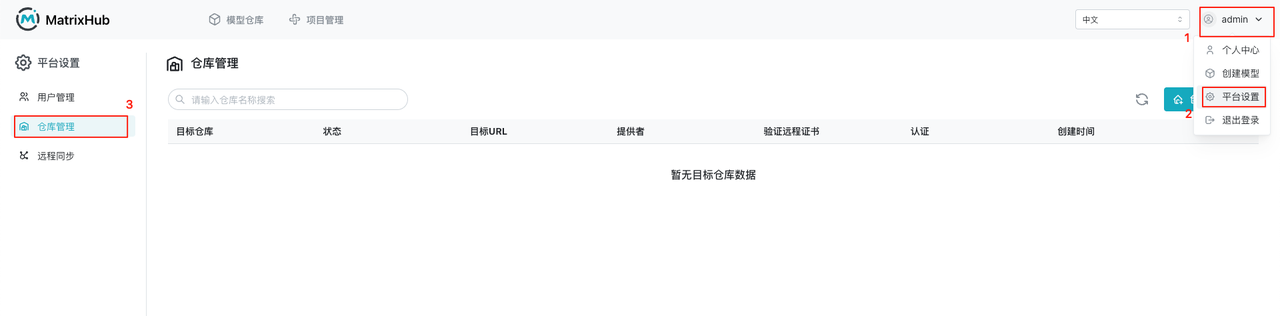
- 创建目标仓库:选择 Hugging Face 作为提供者,填写仓库名称
hf,输入目标 URLhttps://hf-mirror.com,勾选验证远程证书,然后点击“确定”。

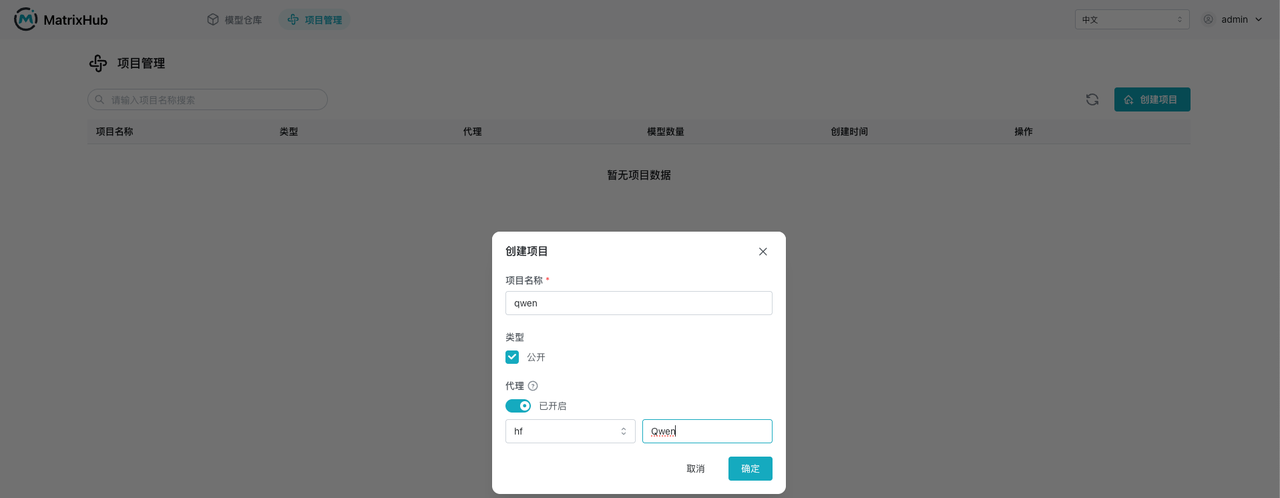
- 进入项目管理,打开项目列表页面。

- 点击“创建项目”:输入项目名称
qwen,设为公开,开启代理,选择仓库,填写代理组织Qwen,然后点击“确定”。
-
拉取模型。
- 第一个节点:约
3m37.318s
- 第一个节点:约

- 第二个节点:约
0m8.500s

- 在 MatrixHub 中查看模型信息。